Data Mesh vs. Data Lakehouse: What’s Best for Your BI Stack?
In the evolving world of enterprise data management, two modern architectures have emerged as the frontrunners for scalable analytics: Data Mesh and Data Lakehouse. Both promise better data accessibility, faster insights, and reduced data silos. But the question facing many organizations today is clear:
Which architecture suits your business intelligence (BI) stack best?
Let’s explore both concepts in depth and help you make a strategic decision.
Understanding the Basics
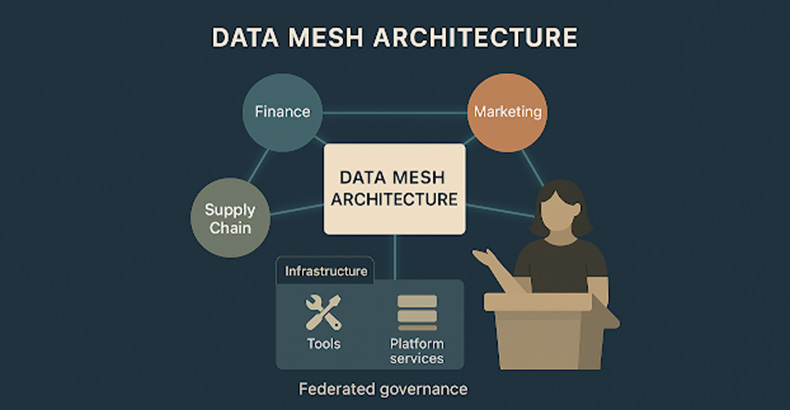
What is a data mesh?
A data mesh is not a technology; it’s a paradigm shift. Instead of centralizing data management, it decentralizes ownership and governance. It treats data as a product and assigns responsibility to domain teams who are closest to the data’s source.

Core Principles of Data Mesh:
- Domain Ownership: Each business unit manages its own data.
- Data as a Product: Teams focus on making their datasets usable, reliable, and discoverable.
- Self-serve Infrastructure: Platform teams provide tools so domains can easily publish and consume data products.
- Federated Governance: Centralized standards (security, compliance) are applied across domains.
What is a data Lakehouse?
A data Lakehouse is an architectural approach that combines the scalability and flexibility of a data lake with the structured performance of a data warehouse. In other words, it brings raw, semi-structured, and structured data into a single platform.

Key Features of a Data Lakehouse:
- Unified Storage: Stores both raw and structured data together.
- Direct BI Access: Supports SQL-based analytics tools without the need for data movement.
- Open Formats: Usually built on open standards like Delta Lake or Apache Iceberg.
- Cost-effective Scaling: Can scale storage and compute separately, reducing costs.
Comparing the Two Architectures

Which One Fits Your BI Stack?
Choose Data Mesh if:
- You’re a large, distributed enterprise with many independent business units.
- Your data domains have strong technical maturity.
- You want each department to own and manage their datasets as products.
- Governance and compliance require federated control.
- You’re shifting from a centralized data team to a self-service, domain-oriented model.

Choose a data lakehouse if:
- You’re aiming to consolidate raw and structured data in a single platform.
- You need direct access for BI and SQL analytics without data movement.
- Your data team is centralized, handling ingestion, storage, and reporting.
- You’re seeking cost-effective scaling for massive data volumes.
- You rely heavily on SQL-based BI tools like Power BI, Tableau, or Looker.
Real-World Scenario
Imagine a global retailer:

- Their finance team needs structured, governed reports.
- Their e-commerce team needs raw clickstream data.
- Their marketing team needs curated campaign data.
With a Lakehouse, all data lands in one platform, optimized for both structured and unstructured workloads.
With a data mesh, each department handles its own data pipelines and products but follows common governance standards.
Choosing between them depends on your team structure, maturity, and strategic goals.
The Future: Can They Coexist?
In reality, many organizations adopt hybrid models:
- A Lakehouse serves as the centralized, scalable platform.
- Data mesh principles decentralize ownership and encourage self-service across domains.
In this way, your BI stack benefits from both architectural strengths.

Conclusion: Strategy Over Technology
There’s no one-size-fits-all answer. Both data mesh and data lakehouse can drive modern BI success, but they approach the problem differently.
If your priority is operational agility and decentralization, lean towards Data Mesh.
If your focus is centralized data management and scalable analytics, Data Lakehouse may serve you better.
FAQs
A Data Mesh is a decentralized data architecture where business domains own and manage their data as products while following shared governance standards.
A data lakehouse is a unified data architecture that combines the flexibility of a data lake with the structured analytics capabilities of a data warehouse.
Data Mesh focuses on decentralized data ownership and domain responsibility, while a data lakehouse centralizes data storage for scalable analytics and BI.
Organizations with distributed teams may benefit from a data mesh, while those seeking centralized data management and SQL-based analytics may prefer a data lakehouse.
Yes. Organizations can use a data lakehouse as the central data platform while applying data mesh principles to support decentralized data ownership and self-service analytics.